Demystifying Kubernetes: A Comprehensive Guide to Master the Fundamentals Part 1.1

Kubernetes:
Kubernetes is a free and open-source technology for container orchestration (commonly referred to as “K8s”). A framework for automating the deployment, scaling, and management of containerized applications is offered by Kubernetes.
A software tool or framework known as a container orchestration platform automates the installation, scaling, management, and coordination of containerized applications across a group of computers or nodes. It offers a centralized control plane to administer and keep track of containers, distribute resources, manage networking, and guarantee high application availability.

Cluster:
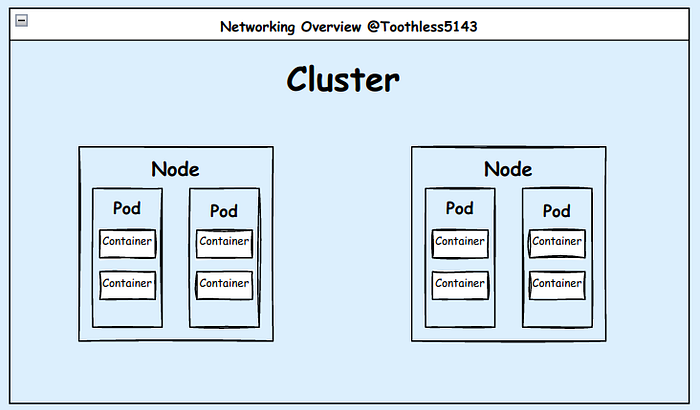
A cluster in Kubernetes is a collection of unique machines, or nodes, that collaborate to run containerized applications. Each node might be either a physical or virtual machine. A master node and a number of worker nodes make up the cluster.
The cluster’s operations are managed and centralized by the master node. It operates the API server, scheduler, and controller manager parts of the Kubernetes control plane. These elements give the master node the ability to manage the scheduling and deployment of containers, keep track of the cluster’s well-being, and carry out other administrative duties.
The actual deployment and operation of containerized apps takes place on the worker nodes. They are in charge of running containers and giving the apps the resources they require to function, such as CPU, memory, and storage.

Control Plane:
The Kubernetes control plane is a group of parts that work together to oversee and regulate the cluster’s operations. The Kubernetes system’s brain, it manages the cluster’s state, upholds desired configurations, and orchestrates various tasks.
The parts of the control plane cooperate to deliver necessary functions and guarantee the cluster’s proper operation. The following are the primary parts of the control plane:
API Server: The Kubernetes API server is a central component of the Kubernetes control plane. It acts as the primary interface for managing and interacting with the Kubernetes cluster. The API server exposes the Kubernetes API, which allows users, administrators, and other components to communicate with the cluster and perform various operations.
Scheduler: The scheduler in Kubernetes is a crucial part of the control plane and is in charge of deciding which worker node in the cluster should run or schedule a specific pod. Its main responsibility is to make sure that pods are assigned to the right nodes in accordance with resource restrictions, availability, and scheduling requirements. The scheduler assesses the available worker nodes and chooses the best node to run the pod when a new pod is formed or when an existing pod has to be rescheduled due to node failures or scaling requirements.
Controller Manager: One of the fundamental elements of the control plane in Kubernetes is the Controller Manager. It is in charge of managing and maintaining the cluster’s desired state by operating a number of controllers. Each built-in controller in the Controller Manager focuses on a different part of the cluster’s resources. These controllers take action to make sure that the cluster’s actual state corresponds to the desired state as stated by the user- or system-defined settings. They continuously monitor the cluster’s state.
etcd: The cluster’s main data store for configuration and state data is the distributed key-value store etcd. In a Kubernetes cluster, it serves as a dependable and highly available storage option, ensuring consistency and fault tolerance.

Nodes:
Nodes are the individual compute resources that form the foundation of a cluster. They are the machines where containers are deployed and executed. Each node represents a physical or virtual machine within the cluster and plays a critical role in running and managing the containerized workloads. Nodes can be physical machines or virtual machines (VMs) that have been provisioned to join the Kubernetes cluster. Each node has its own operating system and resources, such as CPU, memory, and storage.
Worker Nodes:
The Kubernetes machines that run the actual containerized workloads and carry out the tasks assigned by the Kubernetes control plane are referred to as worker nodes (also known as worker or worker machines). They are in charge of operating containers and managing the related resources on a physical or virtual machine level. They make up the cluster’s computational resources.
The following are some essential details concerning Kubernetes worker nodes:
Container Runtime: The program in charge of maintaining and operating containers on the cluster’s worker nodes is known as the container runtime. In order to construct and maintain container instances, it is an essential component that works directly with the kernel of the host operating system.
Kubelet: Kubelet is a component of the Kubernetes architecture responsible for running and managing containers on individual worker nodes within a Kubernetes cluster. It runs on each worker node and interacts with the master node and controls the containers running on that specific node. It acts as an agent, working in conjunction with the control plane, to manage container lifecycles, execute containers, monitor their health, and ensure the desired state of the cluster. It communicates with the Kubernetes control plane to ensure that containers are started, stopped, and monitored according to the desired state defined by the cluster’s configuration. The Kubelet’s role is to maintain the health and lifecycle of containers on its assigned node.
The main responsibilities of the Kubelet include:
- Pod Lifecycle Management: The Kubelet is responsible for managing the lifecycle of pods, which are the smallest deployable units in Kubernetes. It communicates with the control plane to receive instructions on which pods to create and destroy. It ensures that the specified containers within each pod are running and healthy.
- Container Execution: The Kubelet interacts with the container runtime, such as Docker or containerd, to start, stop, and monitor containers. It translates the pod specifications received from the control plane into specific container runtime commands to ensure that the requested containers are properly executed.
- Resource Management: The Kubelet monitors the resource usage of containers on its node, including CPU, memory, and storage. It reports this information back to the control plane, which helps with making scheduling decisions and maintaining the desired state of the cluster.
- Health Monitoring: The Kubelet continuously monitors the health of containers running on its node. It performs health checks to detect container failures and takes appropriate actions to restart failed containers or notify the control plane about any issues.
- Image Management: The Kubelet ensures that the container images required by the pods are present on the node. It pulls the necessary container images from container registries, such as Docker Hub or a private registry, and caches them locally for efficient execution.
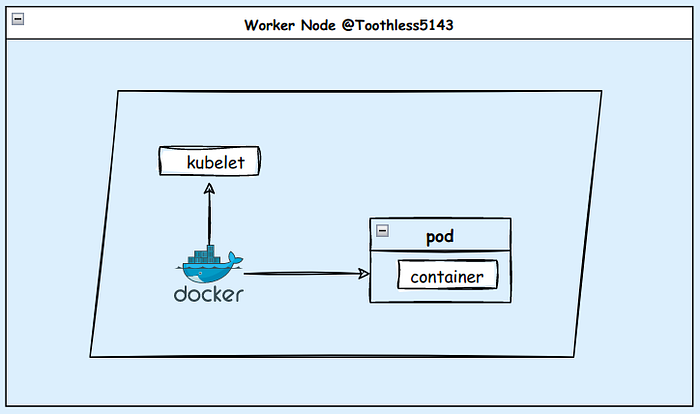
Pods:
A crucial component of Kubernetes, pods offer a logical grouping of containers with scheduling and shared resource capabilities. Within the Kubernetes cluster, they facilitate effective containerized application scaling, management, and communication.
A pod is the smallest and most fundamental deployment unit in Kubernetes. It denotes a collection of one or more closely related containers that utilize the same network namespace, storage volumes, and operating system requirements.
In Kubernetes, scheduling decisions are made at the pod level because pods are the atomic unit of scheduling. Pods of containers are always planned for and deployed on the same worker node in the cluster. They can interact with each other using localhost because they have the same IP address.
Pods in Kubernetes offer the following advantages:
- Encapsulation: Pods combine shared resources like network and storage from one or more containers as well as one or more pods into a single, cohesive unit. As a result, managing and deploying connected containers as a single unit is made simpler.
- Communication and Co-location: Localhost communication between containers in a pod makes inter-container communication easier. Co-locating containers in the same pod lowers network overhead and latency.
- Shared Resources: Containers within a pod can communicate across the loopback interface since pods share the same network namespace. They can also share storage volumes, allowing containers in the same pod to share data with one another.
- Scalability: By making many copies of a single pod, pods can be readily scaled horizontally. This makes scaling and load balancing of containerized applications possible.
- Atomicity and Consistency: Because containers in a pod are always scheduled concurrently, this ensures atomicity and consistency as they are created, modified, or removed. As a result, a pod’s containers are always in sync with one another and retain a constant state.
It’s vital to remember that pods are thought of as temporary and discardable. The Kubernetes scheduler has the ability to create, delete, or reschedule them depending on resource availability, scalability needs, and other criteria. In order to store persistent data, pods should not be regarded as long-lived entities.
Deployments:
Deployments are a high-level resource object in Kubernetes that are used to control the installation and scalability of applications. A collection of replica Pods’ desired state can be defined and managed declaratively and robustly via deployments.
The following are some essential details about Kubernetes deployments:
- Application Deployment: In a Kubernetes cluster, deployments let you specify and control the deployment of apps. They include the number of replica Pods to be built, together with additional configuration information, and they indicate the desired state of the application.
- Replica Sets: Replica Sets are created and managed by Deployments, who make sure the necessary number of replica Pods are active and accessible. Replica Sets serve as a model for building and scalability of Pods according to the configuration of the Deployment.
- Rolling Updates and Rollbacks: Rolling updates and rollbacks are supported by deployments, allowing you to upgrade an application’s image or configuration with the least amount of downtime possible. Deployments gradually swap out outdated Pods for new ones during a rolling update to ensure a seamless transition. You can quickly revert to an earlier deployment if a problem occurs.
- Scaling: Scalability is a feature that deployments include by default. Depending on the need for resources, you can adjust the deployment’s configuration or use short commands to scale the number of replica Pods up or down. The number of Pods is automatically modified by Kubernetes to match the provided replica count.
- Self-Healing: To maintain the appropriate number of replica Pods, Kubernetes automatically replaces a managed Pod that fails or becomes unresponsive. This self-healing ability contributes to the application’s continued availability and resilience.
- Labels and Selectors: Deployments employ labels and selectors to specify the group of Pods they are responsible for managing. Labels are key-value pairs that are associated to Pods and give you the ability to group and choose Pods according to particular standards. Deployments use selectors to locate and control the related Pods.
In Kubernetes, deployments are a potent tool for controlling application scaling, upgrades, and deployments. They make it simpler to manage and scale complicated containerized workloads by offering a declarative and automated method for maintaining the required state of applications.
Services:
Services are an abstraction that provide load balancing and network connectivity to a collection of pods. For interacting with and gaining access to the Pods that are a component of a specific application or microservice, they offer a reliable and consistent endpoint.
The following are some essentials concerning services in Kubernetes:
- Pod accessibility: Using a label selector, services let you expose a collection of Pods as a single network endpoint. This makes it feasible for other components to access the Pods from inside or outside the cluster without needing to know their precise IP addresses or locations.
- Load Balancing: Load balancing is a feature that services offer for the Pods that meet the label selector. The Service intelligently splits up incoming network traffic across the available Pods to ensure more evenly dispersed requests and improved resource usage.
- Service Discovery: Services allow for the automatic finding of Pods that are associated with a specific application or service. Clients can find and connect to the Service by using its DNS name or IP address, and Kubernetes will handle traffic routing the right set of Pods.
- Techniques for Service Discovery and Load Balancing: Depending on the kind of Service, Kubernetes uses a variety of techniques for service discovery and load balancing. These strategies include IP-based load balancing, environment variables, and DNS-based name resolution.
- Headless Services: Kubernetes enables headless Services in addition to the standard clustered Services. Load balancing is turned off and direct connection with specific Pods is permitted by headless services. They’re frequently employed for stateful programs that need direct access to particular Pods.
- Types of Services: Varied types of services are supported by Kubernetes to fulfill varied networking needs, including:
- ClusterIP: The default service type, only available within the cluster, is ClusterIP.
- NodePort: Allows external access to the Service by exposing it on a static port on each node’s IP address.
- LoadBalancer: Provides a load balancer from a cloud provider to distribute outside traffic to the Service.
- ExternalName: Direct DNS-based access to an external resource is made possible by ExternalName, which maps the Service to an external DNS name.
Replication Controllers:
Replication Controllers (deprecated): The replication management feature in Kubernetes’ prior iteration was known as Replication Controllers. They are no longer supported in favor of Replica Sets but are still available for compatibility. Based on a template definition, Replication Controllers are in charge of maintaining a certain number of replica Pods. They keep an eye on the active Pods and proactively add or remove Pods as needed to maintain the target replica count.
The most recent and suggested method for managing Pod replication in Kubernetes is Replica Sets. With more sophisticated selector choices, they are an improved form of Replication Controllers. To identify the Pods they control and make sure the desired number of duplicate Pods is kept, duplicate Sets employ label selectors.

Namespaces:
Namespaces are a technique for Kubernetes to logically divide and isolate resources within a cluster. They offer a way to group and divide various workloads, teams, or projects that are running in the same Kubernetes cluster. Within a real Kubernetes cluster, namespaces offer a virtualized environment similar to a cluster. They make it possible for several teams or projects to work side by side and independently of one another.
Each namespace is equipped with its own collection of resources, including Pods, Services, Replica Sets, Deployments, ConfigMaps, Secrets, and more. These resources are namespace specific and cannot be used or accessed by resources from different namespaces. Resources have distinctive names that are specific to that namespace. A “web” Pod in the “production” namespace, for instance, won’t clash with a “web” Pod in the “development” namespace. Namespaces offer a means of preventing naming conflicts and guaranteeing the uniqueness of resource names.
Resources are created in the default namespace when they are created without a namespace being specified. If no explicit namespace is supplied in a command or setting, the default namespace is applied. Using the Kubernetes API or command-line tools like kubectl, namespaces can be established, modified, and destroyed. Namespace management allows cluster administrators to assign resources and manage access rights for various teams and applications.

StatefulSet:
A resource object for handling stateful applications is called a StatefulSet. In order to guarantee reliable network identities and permanent storage for each Pod, StatefulSets provide assurances regarding the ordering and uniqueness of Pods.
StatefulSets are created to handle stateful applications, which often need persistent storage and dependable network identities. A few examples of stateful applications are message queues, databases, and key-value stores. StatefulSets make guarantee that Pods are built and scaled in a controlled and predictable way. New Pods are produced or terminated in a sequential order, and each Pod in the StatefulSet is given a distinct ordinal index. Based on its ordinal index, each Pod in a StatefulSet has a consistent hostname and DNS address. This offers a network identification that is constant across Pod restarts or rescheduling.
To offer persistent storage for each Pod, StatefulSets support the usage of Persistent Volumes (PVs) and Persistent Volume Claims (PVCs). Data durability is guaranteed even if a Pod is restarted or rescheduled because to the StatefulSet’s ability to provide each Pod with a dedicated storage volume. StatefulSets establish a headless Service by default that enables direct network communication to specific Pods utilizing their reliable network identities. This makes it possible for client applications to connect to certain Pods in the StatefulSet in order to read from or write to them.

ConfigMaps and Secrets:
Kubernetes objects called ConfigMaps are used to store configuration information that may be used by apps operating inside containers. Both mounting configuration files and key-value pairs can be used to construct them. ConfigMaps offer a practical method for handling application configuration independently from container images and enable dynamic modifications without relaunching the connected Pods.
Kubernetes objects called secrets are used to store private data like TLS certificates, API keys, and passwords. Within the cluster, they are safely encoded and kept. Similar to ConfigMaps, Secrets are consumable by apps and offer a secure method of managing and distributing sensitive data to containers without exposing it in plain text.
ConfigMaps and Secrets both make it possible to decouple configuration and private data from container images, enhancing the flexibility, security, and simplicity of managing these resources in a Kubernetes environment.
Persistent Volumes (PV) and Persistent Volume Claims (PVC):
Persistent storage for applications running in containers is made possible by the Kubernetes components persistent volumes (PV) and persistent volume claims (PVC).
PVs are a type of storage that may be assigned to and used by applications inside a cluster. They are either statically or dynamically provisioned by the cluster administrator. PVs offer a storage resource that is autonomous and durable, lasting past the lifespan of any given Pod.
PVCs (Persistent Volume Claims) are requests made by applications to utilise a particular type and quantity of storage from the available PVs. They serve as a request for storage resources and specify the capacity, access mode, and storage class of the PV that is desired. Applications can dynamically bind to the best PV to meet their storage needs thanks to PVCs.
Kubernetes offers a straightforward and adaptable method for managing persistent storage for applications through the use of PVs and PVCs. In contrast to PVCs, which enable applications to smoothly request and use the necessary storage resources, PVs decouple storage provisioning from application deployment.
Ingress:
A Kubernetes resource called Ingress offers access to cluster services from the outside world. It serves as a gateway for traffic, directing incoming HTTP and HTTPS requests to the proper services in accordance with predefined criteria.
Using Ingress, you may create rules for traffic routing that take into account hostnames, routes, and other factors. It makes managing external access more easier by enabling the exposure of different services on a single IP address. To enable secure communication with services employing TLS/SSL certificates, Ingress additionally supports SSL termination.
When deploying an Ingress controller, which is in charge of carrying out the Ingress rules and managing incoming traffic, you can use Ingress. Nginx Ingress Controller and Traefik are two examples of well-known Ingress controllers.
Horizontal Pod Autoscaler (HPA):
A Kubernetes feature called the Horizontal Pod Autoscaler (HPA) dynamically adjusts the number of Pods in a Deployment, ReplicaSet, or StatefulSet based on resource usage. It contributes to ensuring efficient resource usage and application performance.
The HPA monitors the Pods’ CPU usage or other configurable metrics and modifies the replica count as necessary. The HPA adjusts the number of copies to meet the desired target when resource utilization reaches or falls below a certain threshold.
The HPA may adapt to changes in traffic or workload demands by dynamically scaling the number of Pods, ensuring that the application has the resources to handle the load effectively. During times of high traffic, it aids in preventing resource shortages and minimizes resource waste.
Secret Management:
Secret management in Kubernetes refers to the safe processing and storage of private data used by apps running within the cluster, such as passwords, API keys, and TLS certificates. As Kubernetes Secret objects, Kubernetes offers a native way for maintaining secrets.
The cluster securely stores and encrypts Kubernetes Secrets. They can be mounted as files or environment variables in containers and are available to authorized apps.
Sensitive information is base64 encoded and stored in the cluster when generating a Secret. It can be updated and maintained using command-line tools or the Kubernetes API. During deployment, secrets can also be generated from outside sources like files or environmental variables.
Secrets can be used to manage and distribute confidential data securely in a Kubernetes context. It ensures that sensitive data is not exposed in plain text and aids in preventing unauthorized access to sensitive data.
Although Kubernetes Secrets offer some degree of security within the cluster, it is still crucial to adhere to best practices for protecting the cluster’s architecture and restricting access to the Secrets themselves.
Logging and Monitoring:
An essential part of running and maintaining a Kubernetes cluster is logging and monitoring. They offer perceptions into the condition, functionality, and conduct of the cluster’s infrastructure and applications. Application and system logs produced by containers and other cluster components are collected and stored as part of logging. Kubernetes offers a number of logging techniques.
Monitoring is the process of gathering and examining data about the operation and behavior of a cluster, of applications, and of infrastructure. Kubernetes offers a variety of monitoring techniques.
Helm:
Helm is a Kubernetes package manager that makes it easier to deploy and manage services and applications. Using pre-configured packages known as Helm charts, it enables you to define, install, upgrade, and uninstall apps in a Kubernetes cluster.
Custom Resource Definitions (CRDs):
Users can extend the Kubernetes API and specify their own unique resources using CRDs, or unique Resource Definitions. New resource types that are particular to your application or domain can be created.
The Kubernetes API can be extended beyond the built-in resource types, such as Pods, Deployments, and Services, with the help of CRDs. You can use them to create custom resource types that fit the demands of your application or infrastructure.
A CRD, or custom resource definition, is a Kubernetes object that specifies a custom resource’s behavior and structure. It details the custom resource’s structure, validation policies, and other metadata.
Signing out,
- Toothless
